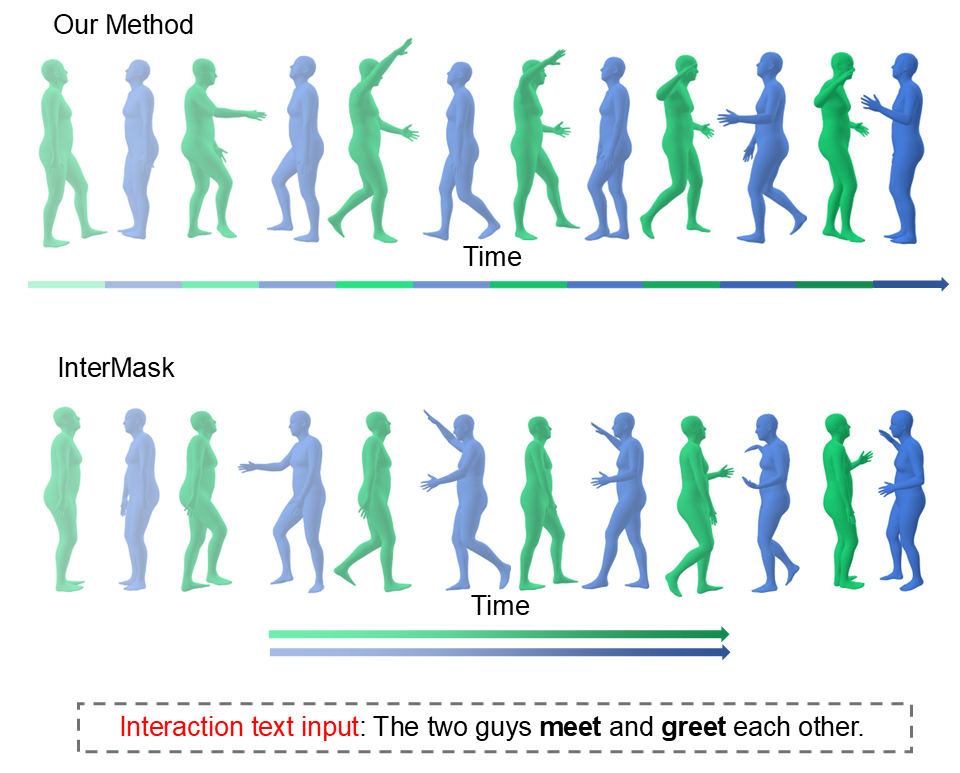
We have recently seen some progress in the current field of human-human interaction generation. However, directly generating complex two-person interactive motions remains a significant challenge. Meanwhile, these models typically employ two independent timelines when generating motions for inter- active scenarios involving two individuals. This design overlooks the temporal dependencies between motions at each timestep and fails to account for the roles of active and reactive participants during the generation process, often resulting in unrealistic and unnatural motions. In this work, we propose HiTMM, a novel framework for Human interaction generation based on Temporal Masked Modeling. HiTMM first decomposes the human interac- tion into two separate single-person motions. Individual motions within the interaction belong to the same type, enabling them to be mapped to a shared latent space through a coarse-to-fine approach that generates multi-layer discrete tokens. We then arrange all tokens of the two interacting individuals along a shared timeline. Subsequently, we employ a masked transformer and a residual transformer to model the base-layer and rest-layer motion tokens. Both the base-layer and rest-layer motion tokens are arranged along a single timeline, allowing the model to learn the role of the initially generated motion. Note that, our model utilizes a shared temporal representation, making it capable of performing temporal editing on specific regions within human interaction sequences. Experimental results show that our model achieves an FID of 5.017 on the InterHuman dataset, surpassing the current state-of-the-art model (vs 5.154 for InterMask), and an FID of 0.373 on the InterX dataset (vs 0.399 for InterMask).
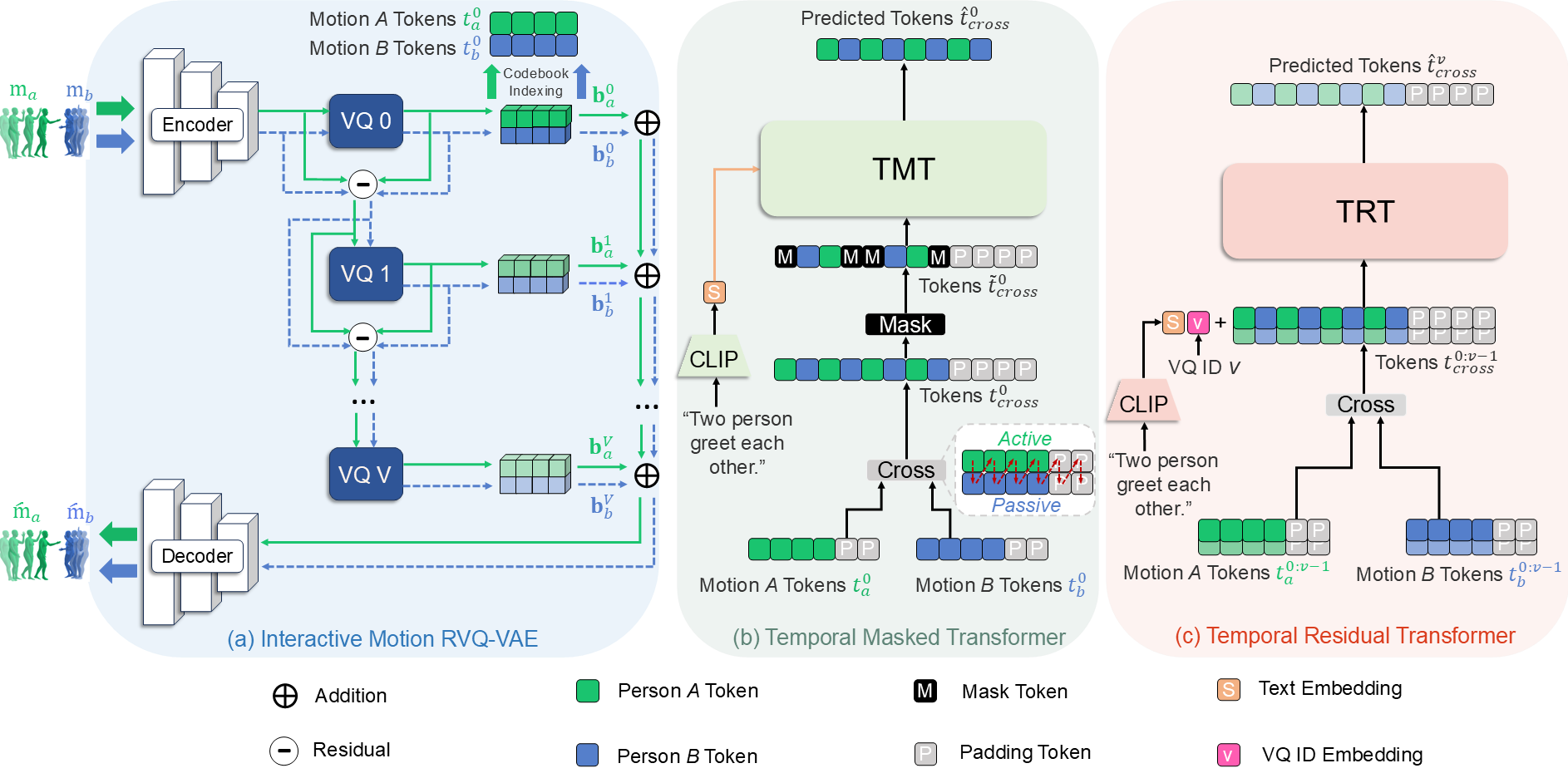
Overview of HiTMM. (a) Here, the motions of each individual are quantized through residual vector quantization (RVQ), resulting in \( t_a^{0:V} \) and \( t_b^{0:V} \). (b) The motion tokens in the base layer of two individuals are first cross-combined to obtain \( t_{cross}^0 \), which is then masked and processed through the TMT for prediction. (c) The remaining tokens, \( t_{cross}^{v>0} \) are progressively predicted layer by layer using the TRT based on the tokens \( t^{0:v-1}_{cross} \) from original layers.
BibTex Code Here